Re-discovering Klavarskribo
Back in college, I majored in piano performance and have mostly been out of practice since then. I tell people that I’ve always had a love/hate relationship with the piano. Recently I picked up a Brahms Intermezzo I learned years ago, so I could play it at the memorial service for my wife’s grandmother. This has got me back to wanting to learn more music again. But I always run into the same mental difficulties when learning music. I long for a more efficient way to load musical information into my brain/body. Deciphering traditional music notation has never been fun for me. Some cases are worse than others. Atonal music is particularly frustrating to learn from the traditional notation.
Consider the first phrase of #2 from Ned Rorem’s Eight Etudes for Piano.

These chords look like a bunch of triads, but that completely obscures what’s really going on. They’re actually very dense chords, and it would be folly to try to play triads with each hand. I got so frustrated after spending a little time trying to (re-)learn this piece, so I decided I needed some way to capture the information after decoding what was written, rather than traversing it repeatedly and hoping some of it would stick, when in reality it would keep falling right out of my brain because I had no way to easily read it.
Short of having someone play it for me repeatedly, so I could watch the correct keys being depressed (or short of owning a Disklavier which could also do that for me), I fired up Vim and started making some ASCII art:
| | | | | | | | | | | | | _ _ _ _ _ o o o _ o o o _ _ _ _ | | | | | | | # | | | | | _ _ _ _ o o o _ o _ o _ _ _ _ _ | | | # # | # | | | | | | _ _ _ _ _ o _ _ o o _ _ _ _ _ _ | | | | | | | | | | | | | _ _ _ _ _ o o o _ o o o _ _ _ _
The rhythm is easy enough to read with traditional notation, so I ignored that part. I just wanted to capture the notes of the chords. The vertical bars provide a template representing the black-key landscape of the keyboard. The circles are white key notes, the # signs are black key notes. After seeing this on the screen, it reminded me of Klavarskribo (Esperanto for “keyboard writing”), which was invented in 1931. I’ve never investigated Klavarskribo very closely. For some reason, I never got inspired by it before today. But now I have this feeling that I’m going to become the next Klavarskribo evangelist. It’s like DDR notation for piano. (Why not?)
Thanks to the fantastic and free KlavarScript software, I mocked up the corresponding phrase (including rhythm this time) in Klavarskribo:
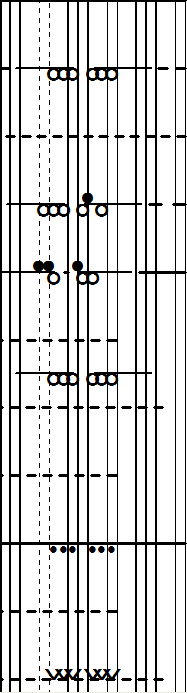
Learning Klavarskribo will be challenging, but I have this feeling that after just a little effort the floodgates will open for me. Most of what I’ll need to do is un-learn what I already know about traditional notation. I see an analogy with imperative programmers trying to learn Haskell (or XSLT) for the first time. They’re trying to overcome “being brain-damaged by years of imperative programming” (their words, not mine). Thankfully, I didn’t have that obstacle in the programming world, because XSLT is where I started. But with music notation, I indeed will need to overcome years of brain damage, not to mention psychological distress, inflicted by traditional notation.






